|
Combining LOPIT with differential ultracentrifugation for high-resolution spatial proteomics
Aikaterini Geladaki, Nina Kocevar Britovsek, Lisa M. Breckels, Tom S. Smith, Owen L. Vennard, Claire M. Mulvey, Oliver M. Crook, Laurent Gatto & Kathryn S. Lilley
Nature Communications, volume 10, Article number: 331 (2019)
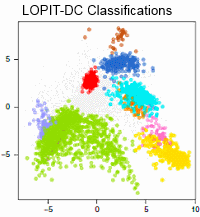
这篇文章介绍了一种在亚细胞器结构、蛋白复合体以及在信号通路中对蛋白进行定位的可靠方法。通过超速差速离心后同位素标记(LOPIT-DC)的方法对细胞器蛋白质的定位是一种基于差速离心的空间蛋白质组学研究途径,与基于密度梯度的 hyperLOPIT方法不同。
该工作流程需要进行细胞分馏,通过差速离心、酶解产生肽段和TMT标记等方法将细胞器分离成10个组分,然后再用LC-MS/MS和MS3进行定量。LOPIT-DC使用TMT多重标记的策略,在单个MS run中可以同时分析所有亚细胞组分。
作者用人骨肉瘤U-2 OS细胞系比较了LOPIT-DC和HyperLOPIT各自产生的蛋白质亚细胞定位图。LOPIT-DC实现了较高的亚细胞分辨率,并且与hyperLOPIT相比使用更少的样品,更短的时间,占用更少的资源。在资源不受限制的情况下,HyperLOPIT提供了最大化的整体亚细胞分辨率,但是在起始材料、时间或资金限制的情况下,更简单和更快的LOPIT-DC方案是一个很好的选择。
|