|
Identification of Protein Isoforms Using Reference Databases Built from Long and Short Read RNA-Sequencing
Aidan P. Tay, Joshua J. Hamey, Gabriella E. Martyn, Laurence O. W. Wilson, and Marc R. Wilkins
J. Proteome Res., published online May 25, 2022
选择性剪接导致转录体的编码区和非翻译区不同,从而产生具有潜在的执行不同功能的蛋白质亚型。然而由选择性剪接产生的具有重要功能的大部分蛋白质异构体仍然是未知的,因此作者研究了使用长读和短读RNA测序数据来建立自定义蛋白质数据库。由于短读可以映射到一个以上的基因组位置,并且几乎不能覆盖几个剪接连接,所以他们设想使用长读RNA测序应该更有助于鉴定蛋白质亚型。
他们使用了从ProteomeXchange下载的人类K562细胞的蛋白质组数据集,将其分别与来自Illumina的短读或Oxford Nanopore的长读RNA测序数据构建的蛋白质数据库进行了检索。
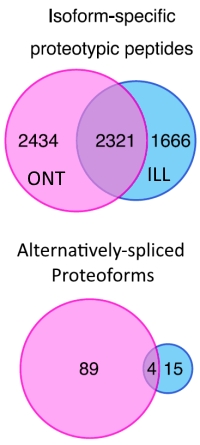
结果显示,二者之间存在互补性,但长读库鉴定出4755条蛋白亚型的特异性多肽,而短读库鉴定出3987条。他们还搜索了由选择性剪接产生的蛋白质异构体,从长读数据库中的39个基因中发现了93个蛋白质异构体,从短读数据库中的10个基因中发现了19个蛋白质异构体。
|